

.webp)
There’s been a lot of hype surrounding GPT-3 since its release in May 2020.
GPT-3 is an AI language generation model created by OpenAI that automatically produces human-sounding language at scale. This third evolution in the GPT line of NLG models is currently available as an application program interface (API). (This means that you’ll need some programming chops if you plan on using it right now.) We’ve talked in the past about how OpenAI’s language models are rapidly improving, and the technology raises major opportunities for marketers.
But many industry publications seemed to go wild for GPT-3, and in the words of OpenAI’s CEO Sam Altman, the hype was “way too much.”

There are tons of questions about the impact of sophisticated natural language generation on jobs, content quality, and the future of technology. But before you get swept up in the hype, let’s level-set on a few truths about GPT-3.
Creating an Article Using GPT-3 Can Be Inefficient
The Guardian wrote an article in September with the title, “A robot wrote this entire article. Are you scared yet, human?” The pushback by some esteemed professionals within the AI was immediate.
The Next Web wrote a rebuttal article about how their article is everything wrong with the AI media hype. As the article explains, “The op-ed reveals more by what it hides than what it says.”
They had to piece together 8 different 500-word essays to come up with something that was fit to be published. Think about that for a minute. There’s nothing efficient about that!
No human being could ever give an editor 4,000 words and expect them to edit it down to 500. What this reveals is that on average, each essay contained about 60 words (12%) of usable content.
Later that week, The Guardian published a follow-up article on how they created the original piece. Their step-by-step guide to editing GPT-3 output starts with “Step 1: Ask a computer scientist for help.”
Since many content teams don’t have a computer scientist on staff, it’s likely that GPT-3 won’t be widely adopted for efficient content production until some of these kinks are worked out.
GPT-3 Can Produce Low-Quality Content
Long before the Guardian published their article, criticism was mounting about the quality of the GPT-3’s output.
Those who took a closer look at GPT-3 found the smooth narrative was lacking in substance. As Technology Review observed, “Although its output is grammatical, and even impressively idiomatic, its comprehension of the world is often seriously off.”
And VentureBeat added, “The hype around such models shouldn’t mislead people into believing the language models are capable of understanding or meaning.”
In giving GPT-3 a Turing Test, Kevin Lacker reveals that GPT-3 possesses no expertise and is “still clearly subhuman” in some areas. Below is an example of GPT-3’s answer when Lacker tried to “stump the AI more consistently” by asking “questions that no normal human would ever talk about.”
 In their evaluation of measuring massive multitask language understanding, here’s what Synced AI Technology & Industry Review had to say:
In their evaluation of measuring massive multitask language understanding, here’s what Synced AI Technology & Industry Review had to say:
“Even the top-tier 175-billion-parameter OpenAI GPT-3 language model is a bit daft when it comes to language understanding, especially when encountering topics in greater breadth and depth.”
GPT-3 Outputs Can Be NSFW
GPT-3 can also, unfortunately, create more insidious results than nonsensical sentences. According to Analytics Insight, “this system has the ability to output toxic language that propagates harmful biases easily.”
The discussion of bias within AI content models isn’t new, and it’s extremely important. It's all too easy for AI models to accidentally generate discriminatory or offensive content. The fact of the matter is, content at scale sounds great on paper, but becomes difficult to police in practice.
The problem arises from the data used to train the model. 60% of GPT-3’s training data comes from the Common Crawl dataset. This vast corpus of text is mined for statistical regularities which are entered as weighted connections in the model’s nodes. The program looks for patterns and uses these to complete text prompts.
As TechCrunch remarks, “just as you’d expect from any model trained on a largely unfiltered snapshot of the internet, the findings can be fairly toxic.”
In their paper on GPT-3 (PDF), OpenAI researchers investigate fairness, bias, and representation concerning gender, race, and religion. They found that, for male pronouns, the model is more likely to use adjectives like “lazy” or “eccentric” while female pronouns are frequently associated with words such as “naughty” or “sucked.”
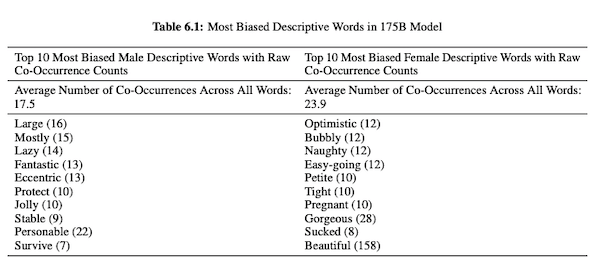
When GPT-3 is primed to talk about race, the output is more negative for Black and Middle Eastern than it is for white, Asian, or LatinX. In a similar vein, there are many negative connotations associated with various religions. “Terrorism” is more commonly placed near “Islam” while the word “racists” is more like to be found near “Judaism.”

Having been trained on uncurated Internet data, GPT-3 output can be embarrassing, if not harmful.
Continue Learning About Natural Language Generation
If you were worried about GPT-3 taking your content production job in the next couple months, hopefully your fears are curbed for now.
With any new technology, the potential for overhyping its capabilities is high. Want to learn more about the truth behind natural language generation? Start with these posts.
