

Introduction
The recurring perception that artificial intelligence, AI, is somehow magical and can create something from nothing leads many projects astray
That’s part of the reason that the 2019 Price Waterhouse CEO Survey shows fewer than half of US companies are embarking on strategic AI initiatives—the risk of failure is substantial. In this series, we’re examining the most common ways AI projects will fail for companies in the beginning of your AI journey. Be on the lookout for these failures—and ways to remediate or prevent them—in your own AI initiatives.
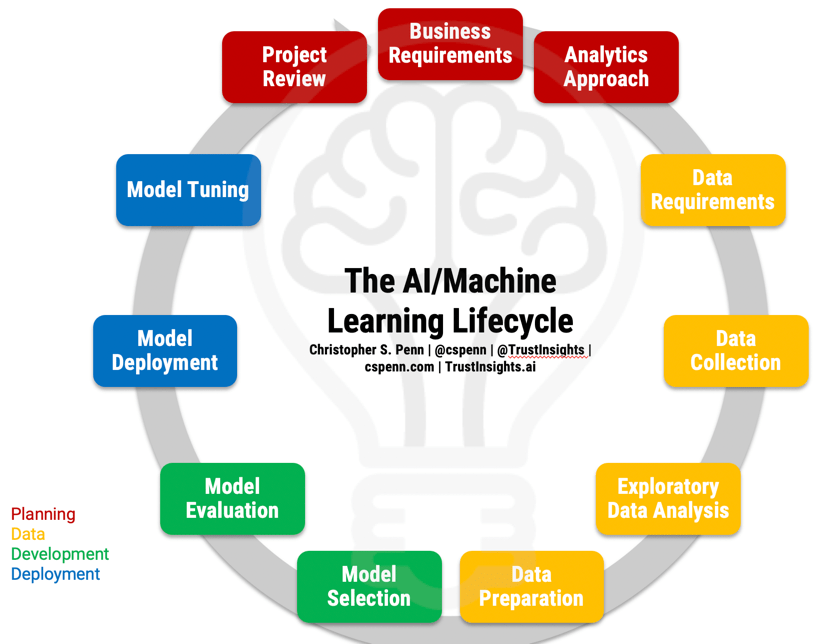
Before we can discuss failures, let’s refresh our memories of what the AI project lifecycle is to understand what should be happening.

Grab the full-page PDF of the lifecycle from our Instant Insight on the topic and follow along.
Part 6: After-Action Reviews and Post-Mortems
In this series, we’ve examined the major breaking points throughout the AI project lifecycle. The one phase we haven’t discussed yet is after-action: what happens after the conclusion of our project. More often than not, we spend no time at all on after-action reviews. We finish the project, deploy the software, perhaps tune it, and then move onto the next item on our to-do lists.
In doing so, we set ourselves up for future failures. Why? After-action reviews give us three major benefits.
First, we look for model drift. Remember that the fundamental output of AI is a piece of software that ingests new data and performs some task on it. Just as no responsible developer would ever release software and then completely abandon it, neither should we release a model and never check back in on it. Validating that our model is still doing what it’s supposed to be doing is essential for reducing risk. Software packages such as IBM Watson OpenScale can assist with the monitoring of our model, but it’s still our responsibility to look at the results and any interpretability/explainability measures we set in place.
Second, we look for process improvements. From kickoff to deployment, what went well? What went wrong? What did we wish we’d known from the beginning? What unexpected obstacles did we fail to foresee? After-action reviews of any software development process help us tune our processes and identify skill/knowledge gaps. When we do after-action reviews well, they provide us with a blueprint for professional development, to fix the areas where we’re weakest.
Third, we look for reuse opportunities. In any software development process, finding appropriate opportunities to reuse code is essential. When we reuse code, we shorten lifecycles without compromising quality, reduce bugs, and accelerate future projects based on the reusable building blocks we created. Nowhere is this more important than in artificial intelligence development. Training an AI model for the first time, especially with deep learning and reinforcement learning projects, can take substantial amounts of time. If we can reuse a model and fine-tune it with new parameters and data instead of rebuilding and retraining it from scratch, we could cut the modeling times of a project by 50% or more. For example, the training of OpenAI’s GPT-2 model took several months, but fine-tuning it can take only minutes or hours at most.
Conducting an Artificial Intelligence Project After-Action Review
After-action reviews, or post-mortems, don’t have to be overly complicated affairs; in many ways, they’re little more than a final project meeting. A facilitator runs the meeting to keep it productive and focused on improvement, and guides the development team through a series of simple questions, such as:
- What was the original plan and goals?
- What actually happened?
- Why did the actual series of events change from the plan?
- What did we learn from the changes?
- What can we improve next time?
The facilitator’s role in an after-action review is straightforward, mainly focused on keeping participants to a set of agreed-upon rules, such as:
- No finger pointing/blame games
- No introducing new information that should have been brought up during the project
- Ensuring even participation from all members
- Keeping discussion focused on learning
In terms of artificial intelligence projects, to ensure maximum benefit, it’s best to conduct an after-action review for each stage of the AI lifecycle. This can be done as you progress through the lifecycle for larger projects, or after the conclusion of the project for smaller projects.
- What was the planned data to be used?
- What data actually got used?
- What model and algorithms did we plan to select?
- What model and algorithms did we actually use? Why?
- Did the model drift? If so, why?
For example, suppose we were reviewing a small AI project, like a natural language processing project. We’d look at each major stage of the AI lifecycle in our after-action review:
Strategy
What was the original goal of the project? To build a topic model using natural language processing so that we could create better content, faster.
What actually happened? We achieved the overall goal.
Data
What data did we plan to use? We planned to use a corpus of documents from industry whitepapers.
What actually happened? The whitepapers were so poorly formatted and so few in number that we needed to source from Reddit posts instead.
The lesson learned here: validate the data sources in advance and ensure there’s enough data to conduct the project.
Modeling
What model did we plan to use? We planned to use the Facebook FastText algorithm to create our topic model.
What actually happened? FastText creates solid collocations, but they are absent of context and order, which means it’s very difficult to create a working model without a lot of human supervision. Using Quanteda’s textstat function worked much better because it preserved word order, and for the purposes of content marketing, word order matters. “Search engine optimization” makes sense. “Engine optimization search” makes no sense, even if they are mathematically identical in terms of frequencies and importance.
The lesson learned here: we should have more clear requirements about how we’re going to use the model so that we can choose the appropriate algorithm up front and not burn cycles testing different algorithms.
Deployment
What deployment strategy did we plan to use? We planned to roll out a shiny app for the model.
What actually happened? With the change in algorithm, we ran into a problem with deploying it using Shiny. Shiny isn’t the right environment or interface for this particular project, so we ended up ditching it and running the model server-side only.
The lesson learned here: again, better requirements gathering would have helped us know what model and algorithm we’d be using, and thus we could have determined whether an end user interface was a possibility or not.
Running after-action reviews for each stage of the AI lifecycle has multiplicative benefits because of the discrete, time-intensive phases of the AI lifecycle. Improvements gained in, for example, the data mining and exploratory data analysis phase can be applied to a broad range of other projects and could potentially improve AI projects in progress.
Artificial Intelligence Projects Series Conclusion
In this series, we’ve examined each stage of the AI lifecycle and what typically goes wrong for people in their first attempts at AI projects. We hope you’ll avoid these common pitfalls in your first projects, and as always, if you’d like assistance, we’re happy to help.
